Training With The Buddy Program
OpenAI to Train Agents with Randomized Social Preferences for Machine Learning
Anyone who plays games, whether cards, video games or golf, learns from the social interactions of the event. The similarities of the game universe and real-life interactions can be useful for training algorithms. A story by Kyle Wiggers for venturebeat.com examines how OpenAI is attempting to include other programs in dual agent learning without giving up their proprietary information.
Many real-world problems require complex coordination between multiple agents — e.g., people or algorithms. A machine learning technique called multi-agent reinforcement learning (MARL) has shown success with respect to this, mainly in two-team games like Go, DOTA 2, StarCraft, hide-and-seek, and capture the flag. But the human world is far messier than games. That’s because humans face social dilemmas at multiple scales, from the interpersonal to the international, and they must decide not only how to cooperate but when to cooperate.
“To address this challenge, researchers at OpenAI propose training AI agents with what they call randomized uncertain social preferences (RUSP), an augmentation that expands the distribution of environments in which reinforcement learning agents train. During training, agents share varying amounts of reward with each other; however, each agent has an independent degree of uncertainty over their relationships, creating ‘asymmetry’ that the researchers hypothesize pressures agents to learn socially reactive behaviors.
RUSP researchers played a “buddy” game to demonstrate the agents’ potential, similar to many of the team player video war games, though a simpler setup with less moving parts. Prisoner’s Buddy, a grid-based game, awards agents for “finding a buddy.” On each timestep, agents act by either choosing another agent or deciding to choose no one and sitting out the round. If two agents mutually choose each other, they each get a reward of +2. If agent Alice chooses Bob but the choice isn’t reciprocated, Alice receives -2 and Bob receives +1. Agents that choose no one receive 0.
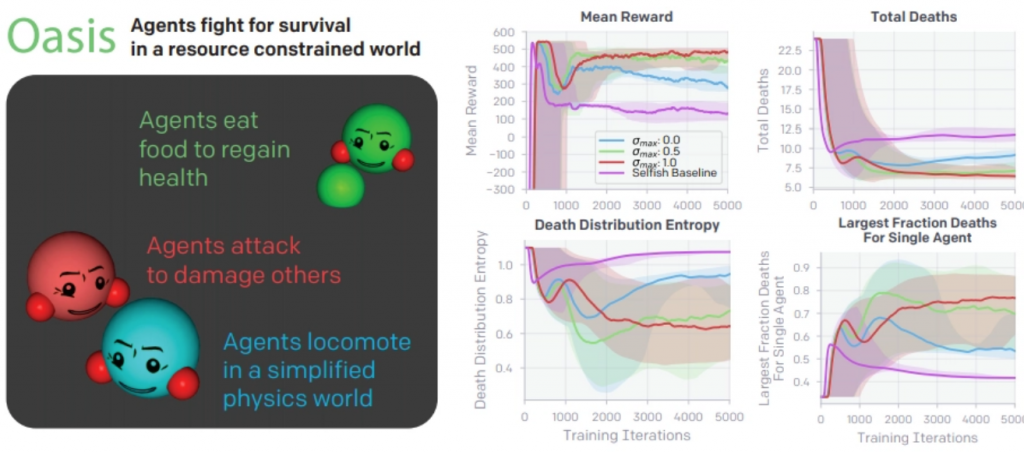
The coauthors also explored preliminary team dynamics in a much more complex environment called Oasis. It’s physics-based and tasks agents with survival; their reward is +1 for every timestep they remain alive and a large negative reward when they die. Their health decreases with each step, but they can regain health by eating food pellets and can attack others to reduce their health. If an agent is reduced below 0 health, it dies and respawns at the edge of the play area after 100 timesteps.
In the game, players only have enough food for two players, so they must gang up on the third.
RUSP agents in Oasis performed much better than a “selfish” baseline in that they achieved higher reward and died less frequently, the researchers report. (For agents trained with high uncertainty levels, up to 90% of the deaths in an episode were attributable to a single agent, indicating that two agents learned to form a coalition and mostly exclude the third from the food source.) And in Prisoner’s Buddy, RUSP agents successfully partition into teams that tended to be stable and maintained throughout an episode.
RUSP has its critics, some saying Oasis is too inefficient. However, most researchers feel this needs further testing and more combinations of agents to produce different results
“Reciprocity and team formation are hallmark behaviors of sustained cooperation in both animals and humans,” they wrote in a paper submitted to the 2020 NeurIPS conference. “The foundations of many of our social structures are rooted in these basic behaviors and are even explicitly written into them — almost 4,000 years ago, reciprocal punishment was at the core of Hammurabi’s code of laws. If we are to see the emergence of more complex social structures and norms, it seems a prudent first step to understanding how simple forms of reciprocity may develop in artificial agents.”
Wiggers’s story explains the research in great detail.
read more at venturebeat.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment