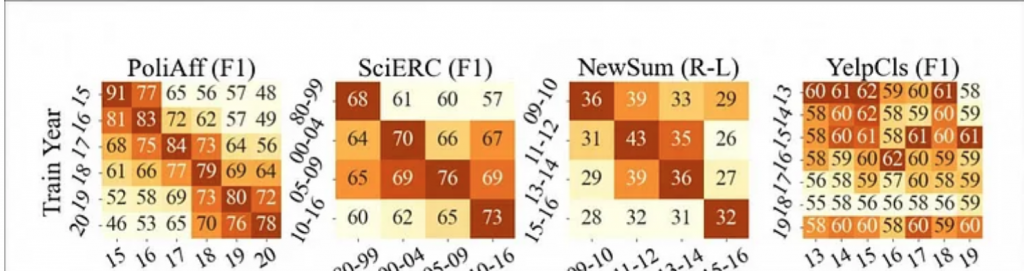
This is a heatmap of temporal degradation across four examples of text material spanning a five-year period. Such mismatches between training and evaluation data, according to the authors of the new paper, can cause a ‘massive performance drop’. Olde English, like that in Shakespeare plays, can throw off the algorithms. (Source: https://arxiv.org/pdf/2111.07408.pdf)
Neural Networks Results Degrade from ‘Temporal Misalignment with Olde English
Researchers at the University of Washington who train algorithms wrote a report on a problem in NLP programs that can take years to present itself. The new research paper was thoroughly covered in a piece on unite.ai.
“Time Waits for No One! Analysis and Challenges of Temporal Misalignment” is the name of the paper that five researchers put together. In the tests, they created to test selected NLP algorithms they found an issue with neural networks which can derail the usefulness of a pre-trained NLP model.
The article is detailed and filled with technical jargon and references that would make more sense to programmers than to the general public. The complicated information is very well broken down in this article by stating the problem, how they tested and then discovered this issue, and what they see needing further study to fix it. Two possible solutions are domain adaptation (DAPT, where an allowance is crafted for the data disparity) and temporal adaptation (where the data is selected by time period) do little to alleviate the problem.
Most current NLP programs are trained and are in constant data sourcing with modern English when that’s the language of the programmers. However, when the networks are searching for data that is written down in slang or in Olde English the program is locking up and losing accuracy. Or temporal misalignment.
The paper states:
‘We find that temporal misalignment affects both language model generalization and task performance. We find considerable variation in degradation across text domains and tasks. Over 5 years, classifiers’ F1 score can deteriorate as much as 40 points (political affiliation in Twitter) or as little as 1 point (Yelp review ratings). Two distinct tasks defined on the same domain can show different levels of degradation over time.’
The paper explains the 80/20 split that most neural networks are trained on and some of its weaknesses.
The Tests
To evaluate temporal misalignment, the authors trained four text corpora across four domains:
Twitter
…where they collected unlabeled data by extracting a random selection of 12 million tweets uniformly spread between 2015-2020, where the authors studied named entities (i.e. people and organizations) and political affiliations.
Scientific Articles
…where the authors obtained unlabeled data from the Semantic Scholar corpus, constituting 650,000 documents spanning a 30-year period, and on which they studied mention type classification (SciERC) and AI venue classification (AIC, which distinguishes if a paper was published in AAAI or ICML).
News Articles
…where the authors used nine million articles from the Newsroom Dataset spanning a period 2009-2016, on which they performed three tasks: newsroom summarization, publisher classification and Media frames classification (MFC), which latter task examines the perceived prioritization of various topics across news output.
Food Reviews
…where the researchers used the Yelp Open Dataset on a single task: review rating classification (YELPCLS), a traditional sentiment analysis challenge typical of much NLP research in this sector.
Conclusion:
“Our experiments revealed considerable variation in temporal degradation across tasks, more so than found in previous studies. These findings motivate continued study of temporal misalignment across applications of NLP, its consideration in benchmark evaluations, and vigilance on the part of practitioners able to monitor live system performance over time.
“Notably, we observed that continued training of LMs on temporally aligned data does not have much effect, motivating further research to find effective temporal adaptation methods that are less costly than ongoing collection of annotated/labeled datasets over time.”
Whether you are deeply involved with this section of AI or if you have some basic interest in the AI the world is relying on, this piece by Martin Anderson is enlightening and informative. AI is not perfect and the researchers have shown even the best algorithms can slow down or get the data twisted. through no fault of its own or in some cases even the original programmers.
read more at unite.ai





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment