OpenAI is testing the use of an earlier version of ChatGPT to monitor the current one in a bid to alert people to any potential superintelligence AI threats. (Source: OpenAI)
Open AI’s ‘Superalignment Team’ Develops Means to Help Humans Prevent Threats by AI
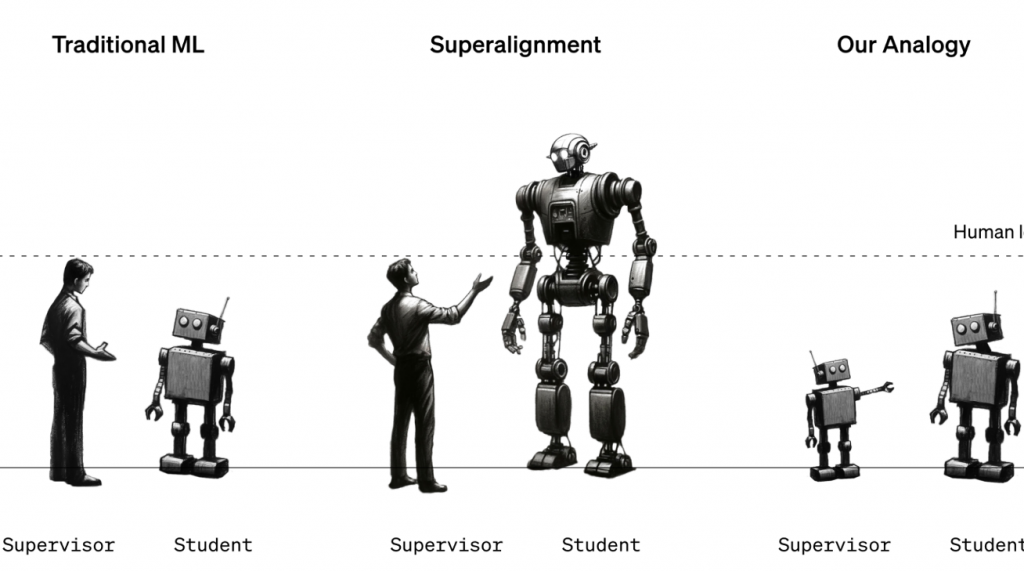
According to a story on MIT’s technologyreview.com, OpenAI has introduced its superalignment team, dedicated to preventing a hypothetical superintelligence from becoming a threat. The team recently published a research paper describing a technique that allows a less powerful language model to supervise a more powerful one, potentially paving the way for humans to oversee superhuman machines. Despite recent controversies, OpenAI remains focused on advancing AI and believes in the rapid progress of AI in recent years. The team anticipates models with human-like abilities and recognizes the challenges that arise with the development of superhuman models.
The team aims to address how to align superhuman models, ensuring they behave as desired. One common technique is reinforcement learning through human feedback, where testers score a model’s responses to train it to produce desirable behavior. However, this approach assumes humans can accurately assess desirable behavior, which may not be true when superhuman models are involved.
To study the problem, the team used GPT-2, a model released by OpenAI five years ago, to supervise GPT-4, the latest and most powerful model. They trained GPT-2 on various tasks and used its responses to train GPT-4. The results were mixed, with GPT-4 outperforming GPT-2 on language tasks but performing less well on chess puzzles. While the approach shows promise, further work is needed to improve its effectiveness.
Thilo Hagendorff, an AI researcher at the University of Stuttgart, finds the idea intriguing, but questions whether GPT-2 is a suitable teacher due to its tendency to give nonsensical responses for complex tasks. He also raises concerns about aligning superintelligence that may possess unknown emergent abilities. Nonetheless, he commends OpenAI for its experimental efforts.
OpenAI aims to involve others in its superalignment initiative and has announced a $10 million funding program to support research on superalignment. The program offers grants to university labs, nonprofits, and individual researchers, as well as fellowships for graduate students. OpenAI believes new researchers can make significant contributions to the field.
Overall, OpenAI’s superalignment team’s research represents a step towards addressing the challenges of superhuman models and aligning them with human goals. While there are limitations and uncertainties, the team’s efforts and commitment to AI safety are commendable.
read more at technologyreview.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment