Google’s DeepMind Excels at Focused Tasks with Narrow Rules
When DeepMind’s AlphaGo computer program beat a professional Go player in Seaul, South Korea in 2016, AI experts hailed its ability to learn the complex game as a groundbreaking event. Most recently, DeepMind has developed Agent57, a computer program with 57 algorithms designed to beat humans playing most Atari video games, but when it comes to solving problems outside of tightly drawn parameters, the AI falls short.
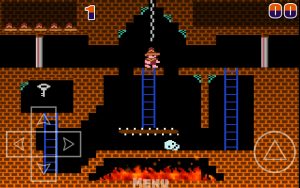
While DeepMind has trained Agent57 to master most Atari games, it still struggles with Montezuma’s Revenge, which requires multiple strategies.
According to a story on MIT’s TechnologyReview.com, the UK company Google acquired in 2014 broadened its game-playing abilities, but it still hasn’t figured out how to get closer to creating a system that, well, thinks outside of the game box.
“Games are a great way to test AIs,” writes Will Douglas Heaven in technologyreview.com. “They provide a variety of challenges that force an AI to come up with a range of strategies and yet still have a clear measure of success—a score—to train against. But four Atari games in particular have proved tough to beat. In Montezuma’s Revenge and Pitfall, an AI must try a lot of different strategies before hitting on a winning one. And in Solaris and Skiing there can be long waits between action and reward, making it hard for an AI to learn which moves earn the best payoff.”
Like most deep learning models, Agent57 isn’t very versatile, according to the article, but rather can only do one thing well. The algorithms can’t make leaps of logic when presented with data that humans can intuitively parse with no problem. This inability to predict cause and effect, spot correlations and infer what will happen keeps AI from reaching the ability to “think.”
“True versatility, which comes so easily to a human infant, is still far beyond AIs’ reach.”
read more at technologyreview.com





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment